


How a recommendation system suggests anything relevant based on the user interest
Publish Date: March 28, 2019How a recommendation system suggests anything relevant based on the user interest?
For a long time, I have been thinking about how shopping websites like Flipkart or Amazon or movie-based platforms like Netflix or even on medium suggest anything based on user interest.
But things are very simple. Unlike my other blogs, this will be little short and will suffice enough to brief you about “recommendation system” and of course with working code.
In this blog post, I will build a movie recommendation system using The movies dataset and deploy it using Flask.
I hear what Google has to say about it.
A recommender system or a recommendation system (sometimes replacing “system” with a synonym such as platform or engine) is a subclass of information filtering system that seeks to predict the “rating” or “preference” a user would give to an item
and putting in a simple language “a recommendation system suggest anything relevant based on the user interest”
The recommendation system is classified into two types Content-Based and Collaborative based recommendation system. Let’s try to understand each one by one.
The idea behind Content-based (cognitive filtering) recommendation system is to recommend an item based on a comparison between the content of the items and a user profile. In simple words, I may get a recommendation for a movie based on the description of other movies.
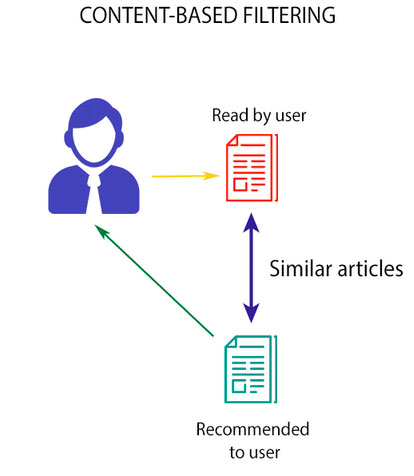
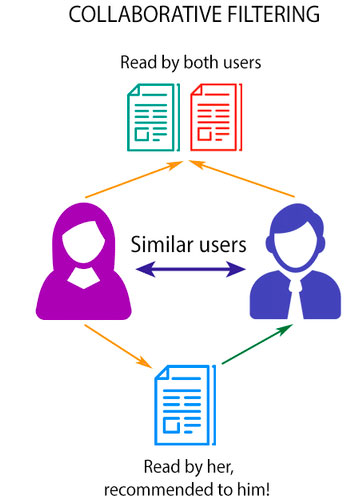
The theory behind collaborative filtering to work with collaboration with user or movie id. For example, there are two user A and B, user A likes movie P, Q, R, S and user B like movies Q, R, S, T. Since movies Q, R and S are similar to both user, therefore, movie P will be recommended to user B, and movie T will be recommended to used A.
We are starting with the understanding of data first. I have used The Movies Dataset. This dataset has metadata on over 45,000 movies and 26 million ratings from over 270,000 users. For our purpose, we will be using movies_metadata.csv and links_small.csv . This dataset describes the one-to-many relationship among the user and ratings. Before we dive in code lets try to figure out our approach towards the solution. For the ease of understanding, I have tried my hands on both (content and collaborative ) filtering approach on the same data set.
For content-based filtering, the approach is relatively simple we have to just convert the words or text in vector form and to find the closest recommendation to our given movie input title using cosine similarity
Let’s begin with the code.
- Reading the dataset from google drive into the data frame. Deleting some absurd data and looking for only those movies Id’s that are present in links_small dataset( look up for movies metadata) and an important part is to merge all the metadata into one which in our case are “overview” and “tagline.”
# mount your drive
from google.colab import drive
drive.mount(‘/content/drive’)
# read the CSV file
md = pd. read_csv(‘drive/My Drive/Colab Notebooks/Movie_recommendation/movie_dataset/movies_metadata.csv’)
# dropping rows by index
md = md.drop([19730, 29503, 35587])
#performing look up operation on all movies that are present in links_small dataset
md[‘id’] = md[‘id’].astype(‘int’)
smd = md[md[‘id’].isin(links_small)]
smd.shape
smd[‘tagline’] = smd[‘tagline’].fillna(‘ ‘)
smd[‘tagline’]
# Merging Overview and title together
smd[‘description’] = smd[‘overview’] + smd[‘tagline’]
smd[‘description’] = smd[‘description’].fillna(‘ ‘)
- Once gathering all data as per our need we have chosen TF-IDF to create the vectorizer of our words. The reason behind choosing this algorithm is to give less weight to the words that are frequently occurring example (the, is, etc.).When calculating the term frequency, we divide the total number of words in the document so that longer documents do not have a greater influence than shorter documents.
from sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer(analyzer=’word’,ngram_range=(1, 3),min_df=0, stop_words=’english’)
tfidf_matrix = tf.fit_transform(smd[‘description’])
Since the implementation of Tfidf is very simple but needs to have few improvements. The words like “hate” and “don’t hate” have a huge difference but still seems the same for the Tfidf.So how can we get out this?
Additionally, Using the concept of bigram or trigram where Tfidf helps us to create vectors in a pair or more which can differentiate the meaning when comes in such pairs.
Once having the vector of all the words we are now ready to step into the algorithm which will eventually tell us who all vectors are similar to each other.
from sklearn.metrics.pairwise import linear_kernel
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
smd = smd.reset_index()
titles = smd[‘title’]
# finding indices of every title
indices = pd.Series(smd.index, index=titles)
Finally, we will create a function which will show top best-recommended movies on the given input. For this task, I have to build a micro-frame (flask) for making web services in Python.
from flask import Flask
app = Flask(__name__)
@app.route(“/”)
def main():
title = request.args.get(‘movie’)
idx = indices[title]
print(“Index”,idx)
similar_scores = list(enumerate(cosine_sim[idx]))
similar_scores = sorted(similar_scores, key=lambda x: x[1], reverse=True)
similar_scores = similar_scores[1:6]
movie_indices = [i[0] for i in similar_scores]
output = []
for item in titles.iloc[movie_indices]:
output.append(item)
return json.dumps(output)
if __name__ == “__main__”:
app.run()
Running the application.
- Navigate to the folder of your code.
- Once you’re in your project directory, run the Flask application by the command python predict.py
- If all went good, you would see the following line on your terminal.

- Copy paste this URL to your web browser, and you are all set to see the output.
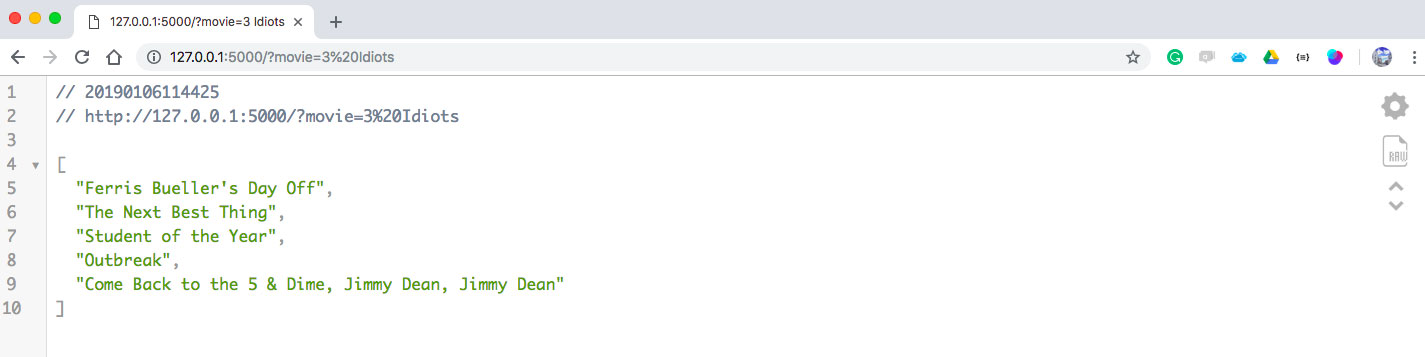
Movies similar to “3 Idiots.”
Closing Note: I hope this blog will help you to build your recommendation system. In my coming blog, I’ll try to build a generic recommendation system using various embedding technique and neural network.
Anchit Jain -Technology Professional – Innovation Group – Big Data | AI | Cloud @YASH Technologies

Anchit Jain
Anchit Jain -Technology Professional – Innovation Group – Big Data | AI | Cloud @YASH Technologies
More From Author.
Related Posts.



Canada’s Thriving Technology Ecosystem – An Overview
Hari Charan Mantravadi

Liquid Template: The perfect tool for object transformation
Kumareswar Kandimalla

The spotlight on Python for real-time embedded systems
Krenal Chauhan

Leverage embedded security IP for your IoT products
Krenal Chauhan

Ushering the age of robots: RPA for your organization
Vrunda Sunil Kamat

Leveraging RPA integration with Oracle ERP for an enterprise
Vrunda Sunil Kamat

DevOps – Driving Excellence in Application Support
Srikanth Karunam

Machine Learning in S/4 HANA – An Overview
YASH Technical PTG Group

A fiery evolution of Fiori
Srihari Tummala
