


In this post, I will give a brief overview of natural language processing, its applications and how we can build the NLP model to solve some real-world problems.
In recent days I came across many text classification problems which include language translation or identifying the mail as spam or not and much more endless examples.
NLP is formed out of 3 components — natural — as exists in nature, language — that we use to communicate with each other, processing — something that is done automatically.
Let’s try solving a real-world problem to understand more about NLP.
Problem Statement
A lot of companies post many jobs every day for seeker’s perusal. They tag these jobs such that they could recommend these jobs to the job seekers having similar skills. These tags are primarily entered manually by the recruiters. But in cases where the recruiter does not have plenty of tags that could hold good for the job, the system, in that case, would like to make suggestions. So, whenever a recruiter posts a job, our system will recommend to the recruiter to associates appropriate tags with the jobs.
Working with NLP, we will try to identify the similar tags that can help recruiters to tag jobs with similar skills.
Through this article, we will cover the following steps to predict the job post tag.

A typical NLP workflow
1. Understanding the data and Text pre-processing
You can download the data from here. The dataset is in JSON format, which will be converted into data frames for better understanding in later stages. The data frame will have features like “Id,” “Tittle,” “Description” and “Tags.” Tittle and description will be used as features and tags will act as a target for us.
Before we go ahead, we need to remove some noise from our dataset. Data cleansing has always proved to be useful to remove some unwanted elements from the dataset. While going through the data, I have figured out what all things can be done to make data more valuable.
- Removing all the HTML tags from job description using BeautifulSoup library.
- Managing special characters such as @,#,- etc.
- Grammatical or spelling errors.
- Working on abbreviations (yrs and years etc.)
2. Text Parsing and Exploratory data analysis
It’s always a good habit to do an exploratory data analysis. After analysis, it is found that in our dataset we have 20,000 job posts with their titles and descriptions and associated tags and a few more things
- Number of training examples: 20000

- Number of unique tags: 788
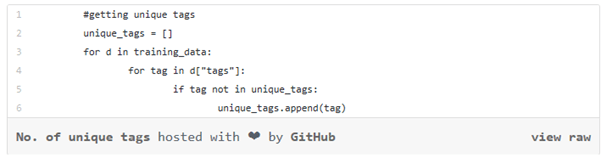
We have a count of total samples and unique tags. It is also very important for us to have balance data, which means all class should have almost equal count.
3. Text Representation and Feature Engineering
In this part of the blog, we will learn about how we can use our text in the model where we need to convert text to vector(a numerical representation of text) — because all ML algorithms work on numbers and we need to find a way to convert text to vector. Luckily we have a few ways that make this task easier for us.
One hot encoding or Bag of words
What is it? It is the technique which represents the text in vector form by first identifying all the unique words from the text and then marking each word of the sentence as one whenever it is found against the bag of unique words. Wait a minute. Let me explain by an example. Collecting all the unique words from all the three sentence “The elephant sneezed at the sight of potatoes.”, “Bats can see via echolocation. See the bat sight sneeze”, “Wondering, she opened the door to the studio.” Below picture will help you to visualize the vector representation of our first sentence “The elephant sneeze…..”.
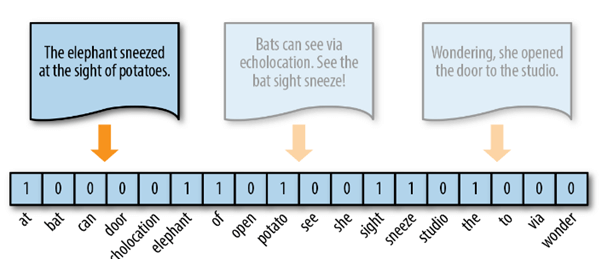
One hot encoding
Why doesn’t it work everywhere?
- Works for small corpus — but if the corpus is huge, the vector size becomes huge.
- Doesn’t take into consideration the position of words.
- Doesn’t understand the similarity between words.
- Doesn’t understand the context of the sentence.
Covering all these drawbacks, Google has once again stepped into AI. Representing the text into a vector with the correct ordering of words and understanding the similarity and context of the word with google universal sentence encoder has helped us to a great extent.
But how does it work?
The Google Universal Sentence Encoder makes getting sentence level embeddings as easy as it has historically been to look up the embeddings for individual words. The sentence embeddings can then be trivially used to compute sentence-level meaning similarity as well as to enable better performance on downstream classification tasks using less supervised training data.


4. Modelling & Training the data
We have training data with us and can be used for training. For this, we have designed a neural network and one way to speed up the training time is to improve the network adding “Convolutional” layer. Convolutional Neural Networks (CNN) comes from image processing. They pass a “filter” over the data and calculate a higher-level representation. They have been shown to work surprisingly well for text.
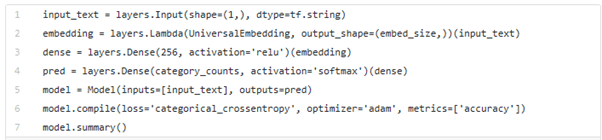
This model might not work well, but when added with LSTM it proved out with better efficiency.
Running around 50 epoch will show a gradual increase in accuracy. However, we might need to switch to another model if this doesn’t work. Using spacy.io can result in better accuracy because this library works more efficiently when we talk about data pre-processing.
You can access the entire code from here.
Closing note: Since this is my first blog on NLP and this is just a gist of what you can do with NLP. In future posts, we’ll talk about other applications of NLP Text Classification using spacy.io.
Anchit Jain -Technology Professional – Innovation Group – Big Data | AI | Cloud @YASH Technologies

Anchit Jain
Anchit Jain -Technology Professional – Innovation Group – Big Data | AI | Cloud @YASH Technologies
More From Author.


Related Posts.

Newborn baby vs. birth of new data
Gopal Krishnaswamy

Why go for a Serverless Data lake architecture
Pranjal Dhanotia

Enterprise Data Management – Maturity Journey
Gopal Krishnaswamy



SAP's Analytics Cloud Benefits for Manufacturing
Rajesh Challa


The added value of SAP Analytics Cloud for businesses
Suresh Suravarapu

Hadoop Installation: Bare metal vs Cloud
Sohan Malegaonkar

Importance of being Business Analyst
Pallav Maheshwari

