


Introduction
Data Lake is a storage concept which supports both structured and unstructured data in its native format. The concept is gaining popularity every day as the data is increasing exponentially. But with emergence, there is some scope for improvements to make it more powerful and efficient data storage technology.
Why Tag?
Metadata tagging helps to identify, organize and extract value out of the raw data ingested in the lake. It can be performed both by custodians, consumers and automated data lake processes. Once tagged, users can start searching datasets by entering keywords that refer to tags. Tagging has an essential role in managing unstructured data like documents in the data lake, in document semantics capturing through tags.
Tagging encompasses —
- Conventional schema information (table/dataset name and description,attribute metadata)
- The data values information through profiling. May include the identification of “business types” on columns or sets of columns
- The relationships/links between attributes of different datasets may be discovered or indicated as tags explicitly by the user
- Higher level, business-specific tagging, and synonyms between tags, which allow for a shared convergence of meaning among users.
Typical Use case scenario
As the data in Data Lake gets stored in its raw format, this could be a tedious task to find the required data efficiently within the time. Metadata tagging is an important process which is a part of Data Discovery through which we can tag every incoming data to find/read the data when required in no time. Following problems can be faced if the data is not tagged in Data Lake:
- Data Search
- No Accuracy
- Speed of data availability
- Implementation Complexities
Even if there is a provision of Metadata tagging, managing it manually is again a dreadful task since the data’s incoming rate is very high.
Possible Solution
Overview
In AWS we can make the Metadata-Tagging process automatic with the help of AWS Lambda. AWS Lambda lets a user run his code through any event without any server management and provisioning.
Implementation
AWS’ Dynamo DB is a NoSQL database which is the perfect choice to store this metadata since fetching metadata should be very fast. Now through every object created bucket event an AWS Lambda function will be invoked and this mapping of Lambda function and event source can be configured in bucket notification configuration.
Flow Diagram
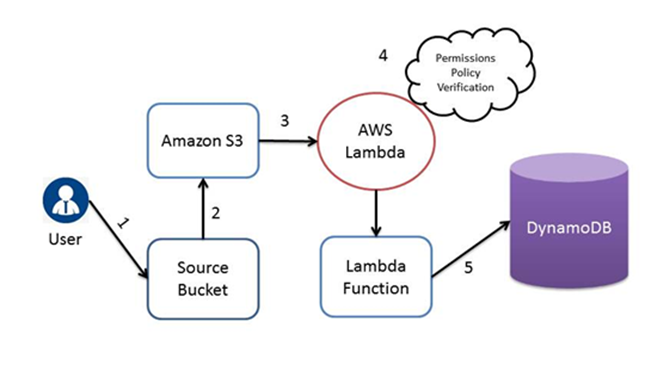
Flow Details
- The user creates an object in source bucket.
- Amazon S3 senses an event of object creation.
- According to event source mapping described in the bucket notification configuration, Amazon S3 invokes the Lambda Function.
- Permissions Policies Verification is performed by AWS Lambda to ensure that Amazon S3 has the necessary permissions.
- After successful verification, Lambda Function gets executed and stores the metadata into DynamoDB.
In practice, discovery tools work by taking a sample of the datasets that are requested to inspect which needs to be indicated as part of this process; profiling and relationship discovery is carried out on this sample. The data lake matures due to the user interaction and feedback through this tagging process. New datasets are produced by business analysts as the data lake gets used also have to be tagged so that these findings can be reused and integrated into new ones. Users can start searching datasets by entering keywords that refer to tags, for example, ‘Plays,’ ‘Orders’, ‘Complaints.’ It can also be a mixture of tags and data values (‘Plays in tags England‘ or ‘Complaints logged by Roy’).
Conclusion
Managing the task of Metadata Tagging manually will always be a major challenge for Data Lake implementation, making this process automated increases the performance and data fetching with greater accuracy can be achieved.
For More Information Download AWS Offering Brochure
Pranjal Dhanotia Senior Technology Professional – Innovation Group – Big Data | IoT | Analytics | Cloud @YASH Technologies

Pranjal Dhanotia
Senior Technology Professional – Innovation Group – Big Data | IoT | Analytics | Cloud @YASH Technologies
More From Author.


Related Posts.


How is Michigan’s Cloud Computing Adoption Fueling Business Growth?
Nagesh Nagasubramanian


Migrating Databases on AWS Cloud
Gautam Gupta

AWS Cost Optimization Tips
Pravish Jain

Assessment of Migrating SAP Workloads to AWS
Kiran Madhu

Multicloud strategy
Pravish Jain

Hybrid Environment – Gotchas
Pravish Jain


SAP tools and services for migrating SAP workloads to cloud
Chaitanya Sopan Patil


Customers leverage holistic benefits with Azure as they move SAP S/4HANA to the cloud
Kumareswar Kandimalla