


Modern data analytics is moving past the Data Warehouse to the Data Lake to utilize emerging technologies for predicting behaviour, not just reporting on what has passed. The organization today though aware of the capabilities of data lake, lack maturity and knowledge of how to implement it. The real challenge facing data lake implementation today is to how to quickly move to a data lake and get actionable insights out of it. They are looking for guidance concerning architecture blue prints, components and processes to implement a successful data lake.
This blog will cover the component architecture of the Data Lake and how these components are connected to each other in a successful Data Lake implementation.
The key components of a data lake: — Data Ingestion — Data Storage — Data Governance — Data Discovery — Data Exploration and Visualization
Data Ingestion
Provide connectors to extract data from a variety of data sources and load it into the lake. A well-architected ingestion layer should:
- Support multiple data sources: Databases, Emails, Webservers, Social Media, IoT, and FTP.
- Support multiple ingestion modes: Batch, Real-Time, One-time load
- Support any data: Structured, Semi-Structured, and Unstructured.
- Flexible enough to support new data sources.
- Provide data curation facilities.

Data Storage
Data storage is one of the key components of a Data Lake architecture.
A well-architected storage layer should:
- Be highly scalable and available.
- Provide low-cost storage.
- Be able to store raw, in-process and curated data.
- Support any data format and allow compression and encryption techniques.
- Provide fast access for data exploration workloads.
Data Management & Governance
Infrastructure and Operations Management
Provisioning, Managing, Monitoring and scheduling your Hadoop clusters.
Security
Security should be implemented at all layers of the lake starting from Ingestion, Storage, Discovery and Consumption through analytics. The basic requirement is to restrict the access to data to trusted users and services only. The following are the key features available for data lake security.
- Authentication
- Authorization
- Accounting
- Data Protection
Data Quality
Data quality is a necessary condition for consumers to get business value out of the lake. A successful data lake implementation must support for Data Discovery, Data Profiling, Data Quality Rules, Data Quality Monitoring, Data Quality Reporting and Data Remediation
Metadata Management & Lineage
Provide data Auditing, Lineage, Metadata Management, Data Lifecycle Management and Policy enforcement and Data Discovery/Search mechanism in a data lake.
Data Lineage
Data lineage deals with data’s origins, what happens to it and where it moves over time. It simplifies tracing errors back to its source in a data analytics process from its journey from origin to destination visualized through appropriate tools.
Data Auditing
It is the process of recording access and transformation of data from risk and compliance perspective.
It involves tracking changes to key dataset elements and capture “who / when / how” information about changes to these elements
Data Discovery/Search
After the ingestion of large data collections, data understanding stage is of paramount importance before one can start preparing data or analysis. Tagging (i.e., metadata tagging) is used to express the data understanding, through organizing, identifying, and interpreting the raw data ingested in the lake.
Data Exploration/Access
The first step for data exploration is dataset discovery. Identification of the right dataset to work with is essential before one starts exploring it. For the data lake to be successful, the data exploration facility needs to provide the following key features:
Flexible Access
Support different mechanisms and/or tools to access data with friendly GUI/Dashboards. Support different type of workloads.
Self-service
The real consumers of data should have the ability to explore the data with minimal dependency on the IT.
Team work
Data lakes work best in a collaborative environment where analysis and findings of one group of users can be shared with other users (or groups), avoiding the need for duplicate effort and improve the overall business outcome.
All above-discussed components work together and play a vital role in Data Lake to create an environment where end users can discover and explore valuable insights out of the data in a secured and managed environment.
Typical Flow in a Data Lake
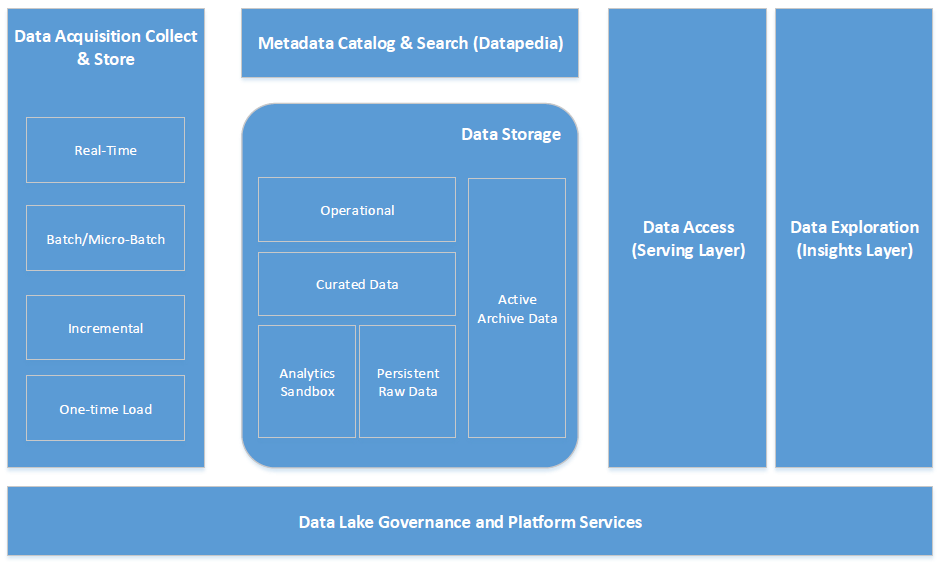
Typically, data from web server logs, data bases, social media is ingested into the Data Lake. Curation of this data takes place by capturing metadata and lineage and making it available in the data catalogue (Datapedia). Security policies and entitlements are also applied.
Data flow into the Data Lake takes place by batch/micro-batch/real-time processing or one-time load activity. Besides, data itself is no longer restrained by initial schema decisions and can be exploited more freely by the enterprise. IT provides a supply-demand model in the form of Data and Analytics as a Service (DaaS). IT takes the role supplier i.e. data provider, while business users (data scientists, business analysts) are consumers.
The DaaS model enables users to self-serve their data and analytic needs. Users browse the lake’s data catalogue (Datapedia) to find and select the available data and fill a metaphorical “shopping cart” (effectively an analytics sandbox) with data to work with. Once access is provisioned, users can use the analytics tools of their choice to develop models and gain insights. Subsequently, users can publish analytical models or push refined or transformed data back into the Data Lake to share with the larger community.
To take advantage of the flexibility provided by the Data Lake, organizations need to customize and configure the Data Lake to their specific requirements and domains. Different applications have different needs for the storage infrastructure. Data must be filtered, restructured, cleaned or at least reformatted, even for basic analysis. The lake provides the capability to do these things as well as to perform more complex processing associated with analytics.
Conclusion
Data Lake is an emerging approach for extracting and placing all data relevant for analytics in a single repository. Ingesting and storing data in native format makes it possible for a larger pool of data be made available for analysis, even if clear business needs are not identified initially.
In our upcoming blog, we will discuss in detail on design consideration and implementation aspect of Data Lake.
Harness big data solutions from YASH to drive better business decisions.
Pranjal Dhanotia Senior Technology Professional – Innovation Group – Big Data | IoT | Analytics | Cloud @YASH Technologies

Pranjal Dhanotia
Senior Technology Professional – Innovation Group – Big Data | IoT | Analytics | Cloud @YASH Technologies
More From Author.
Related Posts.


Data and AI: Essential skills every Big data architect needs
Kumareswar Kandimalla

Building a Data platform – best practices
Ankur Jain


Auto-Tagging data in Data Lake on AWS
Pranjal Dhanotia

SAP HANA Data Migration Essentials
Vamsi krishna

Emergence of Artificial Intelligence and Big Data in Healthcare
Damian Bonadonna

Process of Predictive Analytics
John Doraswamy Bonam

BI Driven Executive – Need for a well-designed Dashboard
Vijaya Kumar Pisupati


Tableau Performance Optimization
Gaurav Mittal

Building Data Lake on AWS
Eshan Jain