


Due to the limitations of non-Unicode code pages, SAP recommends a conversion to Unicode, especially when upgrading systems to Netweaver 7.0 (ERP 2005) and higher releases. However, problems can occur after any upgrade, even without applying new applications. For example, in the case of existing applications, they are re-designed based on new technologies. The problems that can arise from limitations of non-Unicode code pages are:
- Only languages that can be covered by one single non-Unicode code page can be supported within each non-Unicode system
- The installed non-Unicode code page does not support some characters used in your language. E.g. Japanese and Traditional Chinese Installations.
- Most technologies used within the SAP application context are Unicode based. An uncontrolled data loss can occur while using these technologies with a non-Unicode SAP system.
- In the modern Code Pushdown paradigm, data processing is shifted from the ABAP application server to the database server. There is a chance that the shifted functionality contains character processing functions. If the character handling of the ABAP application server differs from the character handling of the database management system, unfavorable effects can arise.
We cover details on Unicode conversion and the technical points that need to be considered while converting non-Unicode to the Unicode system.
What are the technical aspects of Unicode conversions?
1. Consistency check for Pooled and cluster tables
Use report SDBI_CLUSTER_CHECK to search for cluster records in cluster tables. These cluster records have to be removed. SAP Note 1348055 describes the report and explains how to proceed when cluster records are found. The runtime of SDBI_CLUSTER_CHECK is dependent on the size of the table clusters. Also, note that very large table clusters might take up to several days.
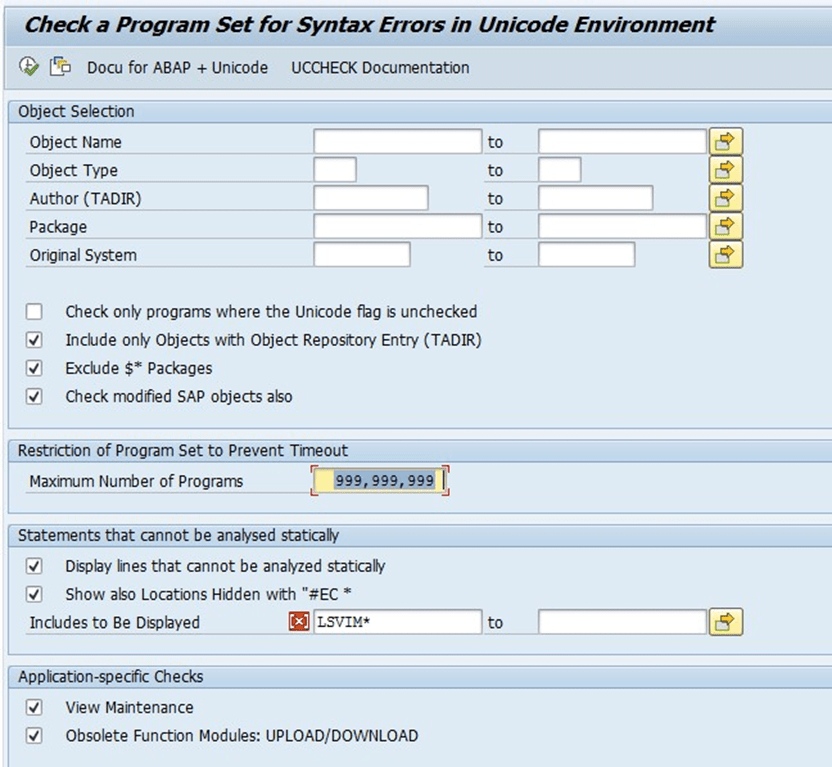
2. Unicode enablement for custom programs using UCCHECK
Only programs that comply with the stricter ABAP 6.10 syntax and semantics will run in a Unicode system. You must ensure:
- All your own programs are ABAP 6.10 compliant
- All SAP programs you modified (SAP Note 548016) – including customer exits that you use (SAP Note 549143) – are ABAP 6.10 compliant
Executing UCCHECK for all SAP programs is not required as some SAP programs are not needed in a Unicode system or will be regenerated in a Unicode system.
Run transaction UCCHECK and enter the programs that need to be verified – All objects in the customer namespace, all objects of type FUGS, and the modified SAP programs.
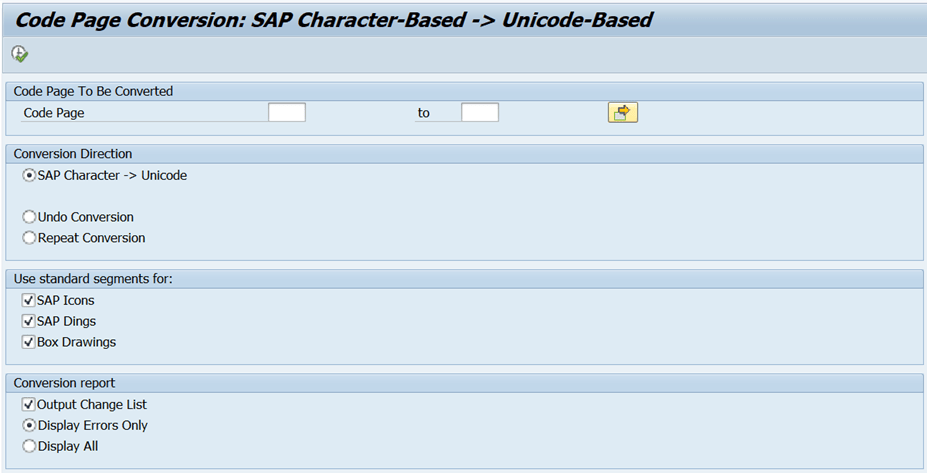
3. Convert customer code pages based on Unicode-based page structure
Customer code pages that begin with “9” must be converted to comply with the new, Unicode-based code page structures. In most cases, such code pages are printer code pages. User report RSCP0126 to transform the customer code pages. A sample selection details screen is:
4. Delete Match code IDs
Run the report TWTOOL01 to find all active Match code IDs. This process is essential because Match ode IDs are not supported in Unicode SAP systems and must be handled before the Unicode conversion.
5. Language Flag Maintenance
As of Release 6.20, all LANG fields have a Data Dictionary (DDIC) attribute Text Lang. (indicator for a language field). This flag specifies that the LANG field determines the character data’s code page in that table. Run report RADNTLANG to set the Text Lang. flag for all tables with one LANG/SPRAS field. This report has to be executed in the background since it may take several hours.
6. Handling OTF Documents after the Unicode Conversion
OTF documents created before the Unicode conversion cannot be processed after the Unicode conversion and cannot be made again in the Unicode system. To save your OTF documents, you can convert them into PDF using the report RSBCS_CONVERT_OTF_FOR_UNICODE.

More From Author.
Related Posts.



Outgrowing Your ERP? How Australian Businesses Can Go Live in 8–10 Weeks
Jai Prakash Nethala


The SAP GROW Story: What Changed, What Stayed, and What It Means for Growing Businesses
Jacinto Arauz Jai Prakash Nethala

Connecting AI Agents to SAP S/4HANA via MCP
Shrina Neema


From Silos to Smart Systems: Why MEA Healthcare Needs Connected Intelligence
Murali Krishna Chilla



YASH F1 Package for SAP GROW Fast: Empowering Midmarket Businesses with Agile Cloud ERP
Jacinto Arauz Jai Prakash Nethala