



Data Lake on Cloud vs. On-Premises
The dynamics of working with data in a Data Lake often calls for rapid provisioning of computing & storage resources, scaling up or down in response to data flows, and processing needs.
Until recently, Hadoop was the primary choice for implementing an on-premise data lake. But, it requires explicit maintenance and administration.
The Cloud well serves these requirements, and it seems like a great alternative which allows for freedom to research new technologies and experiment with solutions without a significant up-front investment. Elasticity, durability, and Scalability are among the most attractive promises of the cloud. Cloud also helps in decoupling your computer and storage systems.
Building a Data Lake on Cloud (AWS)
AWS Cloud provides the building blocks required to help customers implement a secure, flexible, and cost-effective data lake. AWS also provides that help ingest, store, find a process, and analyze both structured and unstructured data.
A data lake should support following capabilities:
- Collection and storage of any data at any scale and low costs.
- Securing and protecting all of the data as well as searching & finding the pertinent information in the central repository.
- Quickly and easily performing new types of data analysis on datasets.
- Querying the data by defining the data structure at the time of use (schema on reading).
There are a variety of advantages to hosting your Data Lake on AWS, including:
Durable, Flexible & Cost-Effective Data Storage
Amazon S3 provides cost-effective, lasting, and flexible data storage solution to store an unlimited amount of data. Storing data in Amazon S3 doesn’t require upfront transformations; you have the flexibility to apply schemas for data analysis on demand.
Simple Data Collection and Ingestion
There’s a variety of ways to ingest data into your Data Lake, including services such as Amazon Kinesis, which enables you to ingest data in real-time. AWS Import/Export Snowball, a security appliance allows you for ingesting data in batches.AWS Storage Gateway, which enables you to connect on-premises software appliances with your AWS Cloud-based storage; AWS DMS, which allows you to migrate your on-premise databases to the cloud; or through AWS Direct Connect, which gives you dedicated network connection between your data center and AWS.
Security and Compliance
AWS provides access to a highly secure cloud infrastructure and a deep suite of security offerings designed to keep your data safe. AWS quickly meet compliance standards such as PCI DSS, HIPAA, and FedRAMP which are fundamental to requirements of the most security-sensitive organizations.
Complete Platform for Big Data
AWS gives you quick access to flexible and low cost IT resources, to scale any big data application like data warehousing, clickstream analytics, fraud detection, recommendation engines, event-driven EL, serverless computing, and IOT processing. AWS ensures that need for making large, upfront investments in time and money to build and maintain infrastructure is reduced. Instead, you can provide exactly the right type and size of resources you need to power big data analytics applications.
Data Lake Services on AWS
Collect & Store
At its core, a Data Lake solution on AWS leverages Amazon Simple Storage Service (Amazon S3) for secure, cost-effective, durable, and scalable storage.
AWS S3 can be used to store all of your data including raw data, in-process/curated data, and processed data while AWS Glacier can be used to keep archival/historical information at an incredibly low cost.
You can quickly and easily collect data into Amazon S3, from a wide variety of sources by using services like AWS Import/Export Snowball or Amazon Kinesis Firehose delivery streams. Amazon S3 also offers an extensive set of features to help you provide reliable security for your Data Lake, including access controls & policies, data transfer over SSL, encryption at rest, logging and monitoring, and more.
Catalog and Search
For efficient data management, you can leverage services such as Amazon DynamoDB and Amazon ElasticSearch to catalog and index the data in Amazon S3.
Using AWS Lambda (Serverless) functions that are directly triggered by Amazon S3 in response to events such as new information being uploaded, you easily can keep your catalog up-to-date.
Processing & Analytics
For analyzing and accessing the data stored in Amazon S3, AWS provides fast access to flexible and low-cost services, like Amazon Elastic MapReduce (Amazon EMR), Amazon Glue (Cluster less ETL), Amazon Athena (Serverless), Amazon Redshift, and Amazon Machine Learning, to rapidly scale any analytical solution. Example solutions include data warehousing, clickstream analytics, fraud detection, recommendation engines, event-driven ETL, and internet-of-things processing.
Access & User Interface
you can create an API with Amazon API Gateway, which acts as a “front door” for applications to access data quickly and securely by authorizing access via AWS Identity and Access Management (IAM) and Amazon Cognito.
Protect & Secure
We can use services like Identity & Access Management (IAM), Security Token Service (STS), Key Management Service (KMS), CloudWatch & CloudTrail to ensure our data security and user identity verification along with monitoring and auditing capabilities.
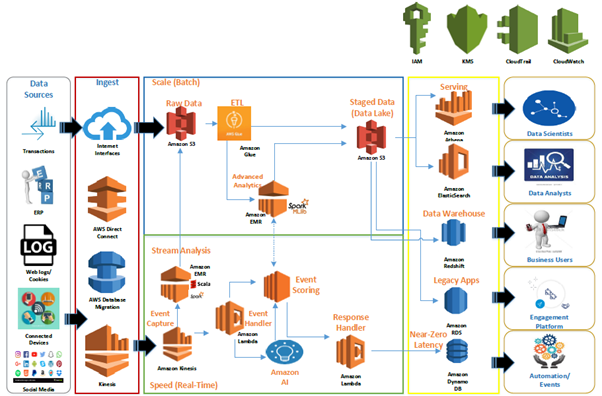
The above architectural blueprint depicts an ideal data lake solution on cloud recommended by AWS.
The raw data is usually extracted and ingested from on-premise systems and internet-native sources using services like AWS Direct Connect (Batch/Scale), AWS Database migration system (One-Time Load), AWS Kinesis (Real-time) to central raw data storage backed by Amazon S3.
Amazon Glue is used to process raw data for ETL, cleansing, tagging and placing it into Staged Data (Data Lake) in batch/scale mode. Data Analysts can then process this data by applying “schema on read” using Amazon Quick Sight or existing BI tools. External users can access this data using API Gateway services.
Real-time events are captured in Speed (Real-time) layer using Amazon Kinesis. Amazon Lambda acts both as an Event Handler to send real-time events for event scoring and getting in-flight enrichment signals as well as a Response Handler to push responses to Amazon Dynamo DB for real-time action with near-zero latency.
Real-time events are also pushed to Raw Data storage (S3) post applying Stream Analytics to be further consumed by Advanced Analytics system running on Spark MLib backed by Amazon EMR cluster. Data scientists produce predictive models & perform analysis on top of this data which can be queried using services like Athena or Elastic Search.
AWS IAM, AWS KMS, AWS CloudTrail and AWS CloudWatch acts as the set of services which enable data governance and security for all data and services in a production environment.
Conclusion
AWS Cloud is a robust technology infrastructure platform with over 80 services designed for security, scale, and availability which are delivered on-demand, via the internet with pay-as-you-go pricing.
By equally managing both data and metadata, the data lake solution on AWS allows you to govern the contents of your data lake, and the flexible, pay-as-you-go, cloud model is ideal for dealing with vast amounts of heterogeneous data. One can quickly provision specific resources and scale needed to power any big data applications, meet demand and improve innovation, thus making AWS as the primary choice for implementing data lake solution on cloud.
For More Information Download AWS Offering Brochure
Eshan Jain – Sr Technology Professional – Innovation Group – Big Data | IoT | Analytics | Cloud @YASH Technologies

More From Author.


Related Posts.


Migrating Databases on AWS Cloud
Gautam Gupta

AWS Cost Optimization Tips
Pravish Jain

Assessment of Migrating SAP Workloads to AWS
Kiran Madhu

Multicloud strategy
Pravish Jain

Hybrid Environment – Gotchas
Pravish Jain


SAP tools and services for migrating SAP workloads to cloud
Chaitanya Sopan Patil


Customers leverage holistic benefits with Azure as they move SAP S/4HANA to the cloud
Kumareswar Kandimalla

